|
|||||||||||||||||||||||||||||||||||||||||||||
![]()
|
Le jeu de GO Deux événements importants en janvier 2016:
|
|
|
||||||||||||||||
|
Le jeu de go est le plus ancien jeu de stratégie combinatoire. Son attrait tient à la
simplicité de ses règles et à la multitude de possibilités de jeux. Le jeu de go est un jeu à information complète; le hasard est exclu. |
Source image: Tromp |
|||||||||||||||
|
Calcul des positions possibles (toutes) Il y a 361 intersections qui
peuvent être, blanches, noires ou vides; soit: 3361 Ce nombre constitue une
borne supérieure de la quantité de positions légitimes. La valeur calculée en
10170 n'est pas bien loin (1,2% inférieure). |
Quantité de coups légitimes et
références
|
|||||||||||||||
![[pic of L19 board]](JeudeGO_fichiers/image012.gif)
Nombre de Tromp: quantité de parties légales au GO 19 x 19 –
Calcul de janvier 2016
|
L19
= 2 0816819938 1979984699 4786333448
6277028652 2453884530 5484256394 5682092741 9612738015 3785256484 5169851964
3907259916 0156281285 4608988831 4427129715 3 193175577 3662039724 7064840935 |
Voir site Number
of legal Go positions – John Tromp
|
|
||
|
Depuis les
premiers programmes de GO apparus
dans les années 60, soit une quinzaine d'années après les premiers programmes
d'échecs, les logiciels ont fait d'énormes progrès, mais le niveau pro est
encore hors de portée en 2014. En 2006,
Rémi Coulom commercialise son programme CrasyStone, le meilleur programme de
GO du marché. Il utilise la technique
de recherche arborescente Monte Carlo. En 2014, les programmes atteignent le
niveau de bon amateur sur plateau de 19x19 (5e ou 6e
dan). |
Les programmes de jeu de GO
utilisent deux méthodes:
Méthode Monte Carlo Elle consiste à faire jouer de
nombreuses parties au hasard par l'ordinateur contre lui-même tout en
favorisant la probabilité de gagner à chaque tour de simulation. |
|
Source: L'Expansion
11/07 /2014
Octobre
2015 – Annoncé en janvier 2016
|
Un ordinateur
(algorithme) bat le champion d'Europe de GO |
|
|
Fan Hui,
un français originaire de Bordeaux, champion d'Europe de GO, est devenu le
premier joueur professionnel à perdre une partie de GO contre un ordinateur (5 à 0). C'est
David Silver et ses collègues du département DeepMind de Google (Londres) qui
ont développé l'algorithme
AlphaGo. Fan Hui
indique que l'ordinateur a joué comme un humain, sans coups innatendus. La
nouvelle a été rendue publique en janvier 2016 par la revue Nature.
Source #AlphaGo Prochaine
étape: la rencontre avec le champion du monde de GO: Sedol Lee (sud-coréen). |
Demis
Hassabis, neuroscientifique anglais et le fondateur de la société DeepMind, une entreprise d'intelligence artificielle,
vendue à Google en 2015: Les règles sont très simples mais il s’agit
probablement du jeu le plus complexe inventé par l’homme, car le nombre de
combinaisons possibles est supérieur au nombre d’atomes dans l’univers. Le
programme utilise à la fois la méthode classique de Monte Carlo et les possibilités d'apprentissage
automatique du deep
learning (apprentissage profond): deux
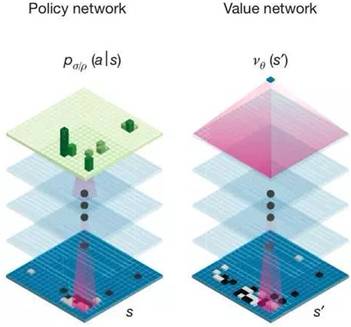
réseaux neuronaux. L'un évalue la situation sur la table et l'autre utilise
cette évaluation pour choisir la meilleure réponse (en anglais: police
network and value network)
Source #AlphaGo L'apprentissage
au sein des réseaux de neurones permet de réduire considérablement le nombre
de coups possibles. La phase d'apprentissage s'est enrichie de millions de
mouvements de joueurs professionnels. |

|
Un ordinateur
(algorithme) bat le champion du monde de GO Lequel est battu
par une IA
à apprentissage profond |
|
|
Les
succès d'AlphaGo En 2015,
AlphaGo bat le champion européen Fan Hui par cinq victoires à zéro. Première fois qu'une machine bâtait
un humain au jeu de go. Le 15 mars 2016,
l'ordinateur bat le champion du monde par quatre parties à une. Lee Se-Dol
(33 ans) est le grand maître Sud-Coréen du jeu de go, un des trois meilleurs
joueurs du monde. Le "combat du siècle" a
été regardée par des dizaines de millions d'amateurs de ce jeu inventé en
Chine il y a près de 3.000 ans. En mai 2017,
AlphaGo bat le champion du monde Ke Jie. Celui-ci confesse avoir changé après
cette défaite face à la machine: bien qu'ayant perdu, j'ai découvert que les
possibilités du jeu de go étaient immenses. |
AlphaGo
Zero, l'IA
autodidacte qui a terrassé AlphaGo (2017) Octobre 2017:
la nouvelle version présentée par Google est encore plus stupéfiante. On
donne à AlphaGo Zero les règles du jeu au programme qui s'entraine contre
lui-même; aucune connaissance préalable. Deux des concepteurs: Demis Hassabis
et David Silver. Ils utilisent la technique du deep learning (apprentissage
profond). Cette
version à auto-apprentissage atteint le niveau humain en quelques heures.
Après quelques jours et cinq millions de parties, cette nouvelle machine bat
AlphaGo par 100 à 0. AlphaGo Zero tourne sur une seule
machine alors que son prédécesseur, AlphaGo, en avait besoin de plusieurs. |
|
Après la victoire de
Deep Blue d'IBM en 1997 sur le champion du monde des échecs, 2017 est une
nouvelle étape du développement de l'IA avec apprentissage profond. Dans certains
domaines, les connaissances peuvent être difficiles à réunir, voire
inexistantes. Il est alors difficile de nourrir les logiciels
d'exemples et de données pour leur permettre de s'entraîner.
L'auto-apprentissage permet de sauter cette étape parfois difficile à mettre
en place. |
|
Voir Actualités 2017
![]()
|
Suite |
|
|
Voir |
|
|
DicoNombre |
|
|
Site |
|
|
Cette page |
![]()